论文链接:https://arxiv.org/pdf/2303.15343
代码链接:https://github.com/google-research/big_vision
摘要
我们提出了一种简单的成对 Sigmoid 损失函数,用于语言-图像预训练 (SigLIP)。与采用 Softmax 归一化的标准对比学习不同,Sigmoid 损失函数仅作用于图像-文本对,无需全局考察成对相似性即可进行归一化。Sigmoid 损失函数同时支持进一步扩大 batch 大小,并在较小 batch size 下表现更佳。结合 Locked-image Tuning 功能,我们仅使用四块 TPUv4 芯片,便在两天内训练出了一个 SigLiT 模型,该模型在 ImageNet 零样本准确率上达到了 84.5%。将 batch size 与损失函数分离,使我们能够进一步研究样本与样本对以及负样本与正样本比例的影响。最后,我们将 batch size 推至极限,达到 100 万,发现增加 batch size 带来的收益迅速减弱,更合理的 32k 批量大小已足够。我们在 https://github.com/google-research/big_vision 上发布了我们的模型,希望我们的研究能够激发进一步的探索,提高语言图像预训练的质量和效率。
1.介绍
使用网络上找到的图像-文本对进行弱监督的对比预训练,正成为获取通用计算机视觉主干模型的首选方法,并逐渐取代在大型带标签多种类数据集上进行预训练。其高阶思想是使用成对数据同时学习图像和文本的对齐表征空间。开创性的工作 CLIP 和 ALIGN 确立了这种方法在大规模数据集上的可行性,随着它们的成功,许多大型图像-文本数据集开始在私有和公共场合开放。
预训练此类模型的标准方法是利用图文对比目标。它对齐图像和文本嵌入,以匹配(正例)图文对,同时确保不相关的(负例)图文对在嵌入空间中不相似。这是通过基于 batch 级softmax的对比损失实现的,该损失应用两次,以对所有图像和所有文本的成对相似度得分进行归一化。softmax的简单实现在数值上不稳定;通常通过在应用softmax之前减去最大输入值来使其稳定,这需要对整个 batch 进行另一次传递。
在本文中,我们提出了一种更简单的替代方案:Sigmoid 损失。它不需要对整个 batch 进行任何操作,因此大大简化了分布式损失的实现并提高了效率。此外,它在概念上将 batch size 与任务定义解耦。我们在多种设置下比较了所提出的 Sigmoid 损失与标准 Softmax 损失。具体而言,我们研究了基于 Sigmoid 的损失,并将其与两种著名的图像文本学习方法结合使用:CLIP 和 LiT,我们分别将其称为 Sigmoid 语言图像预训练 (SigLIP) 和 Sigmoid LiT (SigLiT)。我们发现,当 batch size 小于 16k 时,Sigmoid 损失的表现明显优于 Softmax 损失。随着训练 batch size 的增加,两者之间的差距逐渐缩小。重要的是,Sigmoid 损失是对称的,只需单次传递,并且典型实现所需的内存比 Softmax 损失更少。这使得 SigLiT 模型能够以一百万的 batch size 成功训练。然而,我们发现,随着 batch size 的增加,性能会达到饱和,无论是 Softmax 函数还是 Sigmoid 函数。好消息是,合理的 batch size(例如 32k)足以进行图像文本预训练。这一结论也适用于超过 100 种语言的多语言 SigLIP 训练。
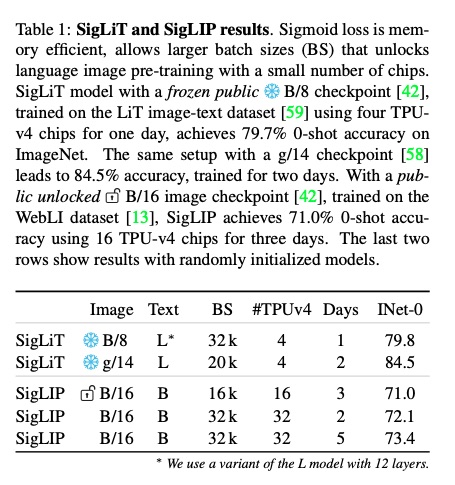
表 1 中,我们展示了需要适量 TPUv4 芯片进行训练的图像文本预训练配置。SigLiT 的效率令人惊喜,仅用一天时间,在四块芯片上,在 ImageNet 数据集上就达到了 79.7% 的零样本准确率。SigLIP 的从零开始训练要求更高,使用 32 块 TPUv4 芯片,在 5 天内达到了 73.4% 的零样本准确率。这与 FLIP 和 CLIP 等先前的研究相比更具优势,后两者分别需要在 256 个 TPUv3 核心上分别花费大约 5 天和 10 天的时间。在对 SigLIP 中预训练的视觉主干网络(如表 1 所示)进行微调时,我们发现禁用预训练主干网络的权重衰减可以获得更好的结果(详情参见图 4)。我们希望我们的工作能够为新兴的语言图像预训练领域铺平道路,使其更容易普及。
2.Related Work
Contrastive learning with the sigmoid loss。先前的一项研究提出了类似的 sigmoid 损失函数,用于无监督降维任务;在对比图文学习领域,绝大多数研究依赖于 [46] 中推广的基于 softmax 的 InfoNCE 损失函数。在监督分类中,sigmoid 损失函数已被证明比 softmax 损失函数更有效、更稳健。
Contrastive language-image pre-training。自从 CLIP 和 ALIGN 将 softmax 对比学习应用于大规模图像文本数据集以来,对比语言-图像预训练变得流行起来。这两个模型在零样本迁移任务(包括分类和检索)上都表现非常出色。后续研究表明,对比预训练模型在微调、线性回归、目标检测、语义分割和视频任务中都能产生良好的表征。
Generative language-image pre-training。除了softmax对比预训练之外,人们还提出了各种替代方案。GIT、SimVLM 和 LEMON 成功地使用生成式文本解码器预训练了模型,而 CoCa 则将这种解码器添加到判别式 CLIP/ALIGN 设置中,从而将两种方法的优缺点结合成一个功能强大的模型。BLIP 进一步提出了 CapFilt,它使用生成式解码器创建更好的字幕,并使用模型的判别部分来过滤图像对。语言-图像预训练是一个非常活跃的领域,一些综述很快就会过时。
Efficient language-image pre-training。另一方面,很少有研究尝试提高语言图像预训练的效率。LiT 和 FLIP 是值得注意的尝试,前者需要预先训练并锁定的主干网络,而后者则通过随机丢弃视觉 token 来牺牲质量。BASIC 和 LAION 尝试扩展 batch size,但通过使用数百块芯片,分别只能达到 16k 和 160k,前者还混合了一个大型私有分类数据集。最近的 Lion optimizer 声称能够降低训练成本并达到类似的质量。
3.Method
在本节中,我们首先回顾一下广泛使用的基于softmax的对比损失。然后,我们介绍成对sigmoid损失,并讨论其高效的实现。
给定一个 mini-batch \mathcal B = \{(I_1, T_1),(I_2, T_2), ... } 的图像-文本对,对比学习目标鼓励匹配对 的嵌入彼此对齐,同时将不匹配对 的嵌入推开。出于实际目的,假设对于所有图像 ,与另一幅图像 相关联的文本与 无关,反之亦然。这种假设通常存在噪声且不完善。
3.1 Softmax loss for language image pre-training
当使用softmax损失来形式化该目标时,训练图像模型 和文本模型 以最小化以下目标:
其中, 以及 。在本文中,我们采用视觉Transformer架构处理图像,并采用Transformer架构处理文本。需要注意的是,由于softmax损失函数的非对称性,我们分别对图像和文本进行了两次归一化。标量的参数化形式为,其中是一个全局可自由学习的参数。
3.2 Sigmoid loss for language image pre-training

我们提出了一个更简单的替代方案,取代基于softmax的对比损失,它不需要计算全局归一化因子。基于sigmoid的损失函数独立处理每个图像-文本对,有效地将学习问题转化为所有组合对数据集上的标准二分类问题,匹配对 标记为正标签,其余对 标记为负标签。其定义如下:
其中 z_{ij| 是给定图像和文本输入的标签,如果它们是配对的,则为 1,否则为 -1。在初始化时,由大量负样本引起的严重不平衡在损失函数中占主导地位,导致初始优化步骤需要大量步骤来尝试纠正这种偏差。为了缓解这个问题,我们引入了一个类似于温度 的额外可学习偏差项 。我们将 和 分别初始化为 和 -10。这确保训练开始时大致接近先验,并且不需要大量的过度校正。算法 1 给出了用于语言图像预训练的 Sigmoid 损失函数的伪代码实现。
3.3 Efficient “chunked” implementation
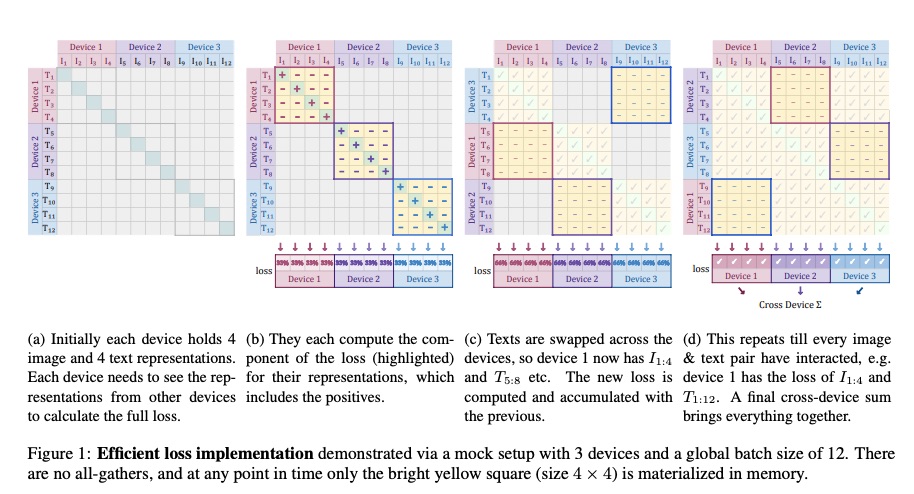
对比训练通常利用数据并行性。当数据被拆分到 个设备时,计算损失需要使用昂贵的全收集算法来收集所有嵌入,更重要的是,需要实现一个内存密集型的 成对相似性矩阵。
然而,Sigmoid 损失函数尤其适用于内存高效、快速且数值稳定的实现,从而改善这两个问题。设每个设备的 batch size 为 ,则损失函数可重新表述为:
对于 Sigmoid 损失来说,这尤其简单,因为每对数据都是损失中的独立项。图 1 展示了这种方法。简而言之,我们首先计算正样本对和 b - 1 个负样本对对应的损失分量。然后,我们跨设备置换表示,使每个设备从其相邻设备获取负样本(next iteration of sum B)。然后针对该数据块计算损失(sum C)。这在每个设备中独立完成,因此每个设备都针对其本地批次 b 计算损失。然后,可以简单地将所有设备的损失相加(sum A)。单个集体置换(for sum B)速度很快(实际上,D 个集体置换通常比 D 个设备之间的两次全收集更快),并且任何给定时刻的内存成本从 |B|2 降低到 b2(for sum C)。通常 b 是常数,因为扩展 |B| 是通过增加加速器数量来实现的。由于 vanilla 损失的计算是 batch size 的二次方,因此它很快就会成为扩展的瓶颈。这种分块方法可以在相对较少的设备上进行 batch size 超过 100 万的训练。